Git 사용법
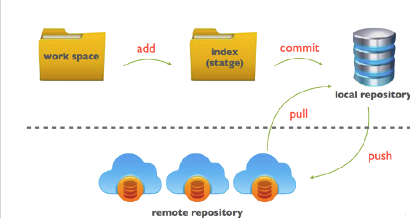
- add
- 변경된 파일의 내용을 index(Stage)로 보냄 - commit
- index의 내용을 HEAD(local repository)로 보냄 - push
- local repository -> remote repository 로 보냄 - pull
- remote repository -> local repository 로 보냄
push, pull 이해를 위한 사용 예시
ex)
집 <-> 회사 동시 작업하는 경우
1. 집에서 작업한 후 git push로 원격 저장소로 보냄
2. 회사에서 작업할 때 작업하기 전 git pull로 원격저장소 내용을 가져와서 동기화한 후
작업을 시작한다. 작업을 완료한 후 git push로 원격저장소로 새로운 버전을 보냄
3. 집에 와서 작업하기 전 git pull로 원격저장소 내용을 가져와서 동기화한 후 작업 시작
회사에서와 마찬가지로 작업을 완료한 후 git push로 원격저장소에 새로운 버전을 보냄
git branch 사용 방법
명령어
- git branch
- 현재 branch를 확인 - git branch [ 브랜치명 ]
- 새로운 branch [브랜치명]을 생성 - git checkout [ 브랜치명 ]
- 현재 속한 branch를 브랜치명 branch로 바꿈 - git log --branches --graph --decorate --oneline
- 현재 브랜치들의 흐름을 그래프로 간단히 보여줌 - git branch -d [ 삭제할 브랜치명 ]
- 브랜치 삭제
branch 사용 예시
예를 들어 현재 브랜치가 main, exp 두 개가 있다.
두 개의 브랜치에서 한 일을 병합하고 싶을 때 어떻게 해야 할까?
만약 main에서 병합하고 싶다면 main 브랜치에서
$git merge exp 명령어를 입력한다.
-> exp 브랜치의 내용과 main 브랜치에서의 내용이 main 브랜치에서 병합된다.
-> < 주의!! > exp 브랜치에는 병합된 내용이 아닌 exp에서 수정한 내용만 들어있다.
위의 내용을 직접 수행해보자. ( 서로 다른 브랜치에서 같은 파일을 수정한 후 수정 내용을 병합하는 과정 )
( 기본 브랜치 : main )
$git branch exp -> exp branch 생성
$git checkout exp -> exp branch로 가서 거기서 소스코드 변경
$git add test.c
$git commit -m "exp에서 변경"
$git checkout main -> main branch로 가서 거기서 소스코드 변경
$git add test.c
$git commit -m "main에서 변경"
$git merge exp -> exp와 main이 main branch에서 병합됨 ( 겹치는 부분을 고친 게 아니라면 자동으로 병합해줌 )
$git push -> 병합한 최종본을 원격저장소로 push
처음 local에서 Git 사용할 때 Git 세팅방법
1. git config -global user.name "git 아이디"
2. git config -global user.email "git 이메일"
3. git config -list -> 아이디, 이메일이 잘 들어갔는지 정보 확인
내 로컬에 있는 프로젝트를 Git에 올리는 방법
( 1, 4번은 처음에만, 나중에 사용할 때는 2, 3, 5번 반복 )
- Github에 저장소 작성 또는 복제 ( git init OR git clone )
git init : 현재 작업중인 디렉토리를 Git 저장소로 변환한다. - 파일의 생성 / 변경 / 삭제를 index(stage)에 추가
git add [ 파일명 ] - 변경 결과를 로컬 저장소에 커밋
git commit -m "Comment" ( git status 명령어로 잘 올라갔는지 확인 가능 ) - 원격 저장소에 push로 반영하기 전 local repository에 remote repository를 연결
git remote add origin [ https://github.com/username/repositoryName ]
( 연결 후 잘 연결됐는지 git remote -v 로 확인 가능 ) - 로컬 저장소를 push해서 원격 저장소에 반영 ( git push )
git push origin [브랜치명]
[원격저장소]
자주 사용하는 Git 명령어
- git status
- 저장소의 상태를 확인하는 명령어 ( 현재 branch의 이름, 추가/변경된 파일 및 디렉토리 목록 표시 ) - git add
- 파일 or 디렉토리를 index(stage)에 추가하는데 사용하는 명령어 - git checkout
- 로컬 저장소의 현재 속한 branch를 바꿔줌 - git clone
- 기존 원격 저장소를 로컬에 다운로드하기 위해 사용
ex) github에 공개된 저장소를 자신의 컴퓨터에 다운로드할 때 사용 - git remote
- 원격 저장소를 조작하는데 사용
git remote -v : 원격 저장소에 대한 자세한 목록 표시
git remote add origin [원격저장소 URL] : 원격 저장소를 추가
git remote remove [ name ] : 원격 저장소 제거 - git reset
- 로컬 저장소의 커밋을 취소하기 위해 사용 ( 잘못 커밋했거나 수정내용 누락이 있을 때 자주 사용 ) - git pull
- 원격 브랜치의 저장소를 가져옴
ex) 로컬 저장소 master 브랜치에 원격 저장소 origin의 master 브랜치 가져오는 경우
-> git checkout master git pull origin master
Git 사용시 자주 발생하는 에러 상황
1. 원격저장소에 local에 없는 새로운 파일이 생겼을 때 local에서 그걸 알지 못하고 그냥 push 하는 경우
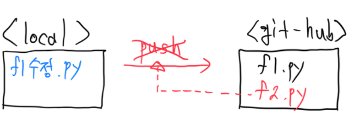
해결 방법
- pull로 원격 저장소의 데이터들을 가져와 내 local 저장소와 원격 저장소를 동기화 시킨 후
push로 수정사항을 원격 저장소에 보내면 해결된다.


